Unlock the full potential of your RDF data with a SPARQL endpoint – learn the basics of this powerful query language and how to access and extract insights from large datasets.

SPARQL (SPARQL Protocol and RDF Query Language) is a query language for retrieving and manipulating data stored in RDF (Resource Description Framework) a W3C standard for representing information as triples (subject-verb-predicate structure) inside knowledge graphs. It is similar in purpose to SQL (Structured Query Language) which is used for relational databases but is designed specifically for the RDF data model. It allows users to write complex queries to extract specific data from an RDF database.
SPARQL offers flexibility, interoperability, expressiveness, and scalability and is well-suited for Linked Data (data distributed across multiple sources). However, in order to query this Linked Data, it needs to be accessible via a SPARQL endpoint.
In this article, we will discuss why a SPARQL endpoint is important and how it can be used to unlock the full potential of RDF data.
A SPARQL endpoint is a web-based service
A SPARQL Endpoint is one of the points of presence on an HTTP network that is capable of receiving and processing SPARQL protocol requests. The SPARQL Protocol defines how to send SPARQL queries and receive results.
The SPARQL Endpoint is identified by a URL that is commonly referred to as a “SPARQL Endpoint URL” and is typically part of an automated SPARQL implementation. The endpoint is typically hosted by the provider of the RDF dataset and can be accessed by anyone with an internet connection.
One of the ways to access these SPARQL endpoints is through cURL, and we talk about it in this article “A valuable resource to unlock the Power of cURL and SPARQL”.
Access and query large RDF datasets
One of the main advantages of a SPARQL endpoint is that it enables distributed access and collaboration on RDF data. Without a SPARQL endpoint, querying an RDF dataset would require downloading and processing the entire dataset locally. This can be a daunting task for large datasets and can limit the number of people who can access and analyze the data.
With a SPARQL endpoint, the data remains on the remote server and can be queried by anyone with an internet connection. This greatly increases the number of people who can access and analyze the data and enables collaboration on RDF data between researchers, organizations, and developers.
Create powerful applications and services
Another advantage of a SPARQL endpoint is that it enables the creation of powerful applications and services that can combine and analyze data from multiple sources. With a SPARQL endpoint, developers can easily query and combine data from multiple RDF datasets to create new applications and services like a web application that combines data from a legislative library catalogue, a museum’s collection, a library catalogue on a specific domain and a government’s open data portal to create a powerful research tool.
Publish data on the web
Lastly, having a SPARQL endpoint allows data providers to publish their data on the web, making it more accessible to a wider range of users and applications. This can help organizations and institutions maximize the value of their data, by enabling reuse, repurposing, and sharing with others.
Some examples of SPARQL Query Services
A SPARQL Query Service is a web-based service that offers an API for performing operations on data represented as RDF and receiving the results.
The service is typically hosted by the provider of the RDF dataset and is accessed via a SPARQL endpoint, similar to a DBMS (Database Management System Application) or a Triple store. It is associated with a URL that identifies its point of presence on an HTTP network, i.e., the address to which queries are dispatched.
The service receives SPARQL queries, processes them against the RDF dataset, and returns the results to the user in a standardized format, such as JSON or XML.
The query service can be used to extract and analyze data from RDF datasets by specifying patterns to match the data, and it can also be used to update, insert or delete data from the dataset.
There are many SPARQL Query Services available online, some examples include:
The LOD cloud diagram cache is a visualization of 1579 datasets with over 16,200 links. Each vertex is a separate dataset structured as a knowledge graph.
DBpedia is part of the Linked Open Data Cloud. The DBpedia data set includes information from Wikipedia infoboxes and categories.

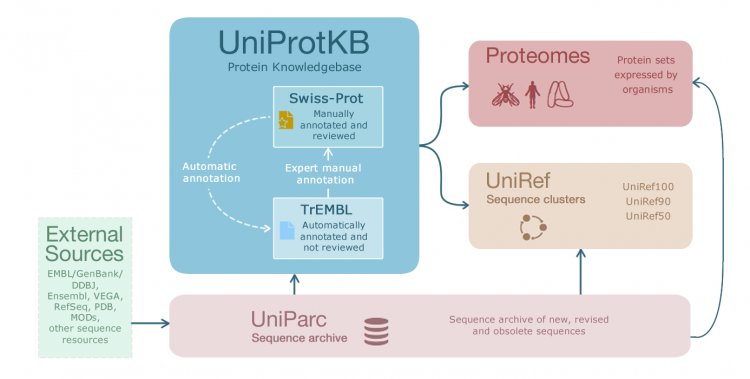
Uniprot is a comprehensive resource for protein information. It is a freely accessible database that provides a wealth of information on proteins, including their sequences, functions, interactions, and structures. It is composed of two main databases: UniProtKB (Knowledgebase) and UniRef (UniProt Reference Clusters).
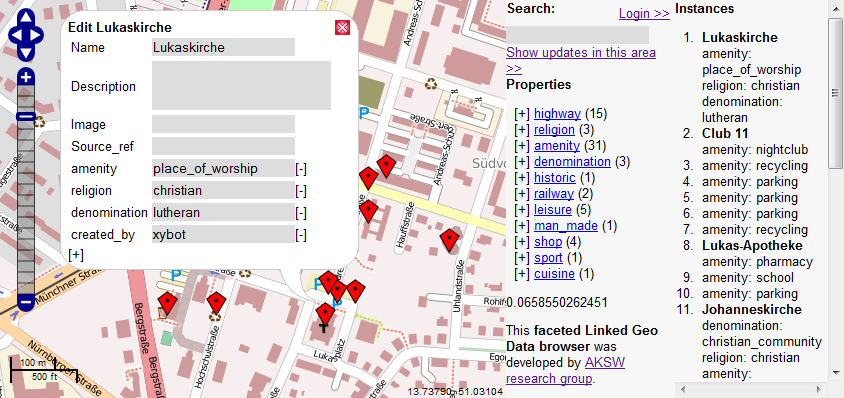
LinkedGeoData is an RDF dataset that interlinks and makes available various sources of geographical data available on the web, such as OpenStreetMap, GeoNames, and others. You can use its SPARQL endpoint to retrieve information on locations, addresses, and other geographical data.
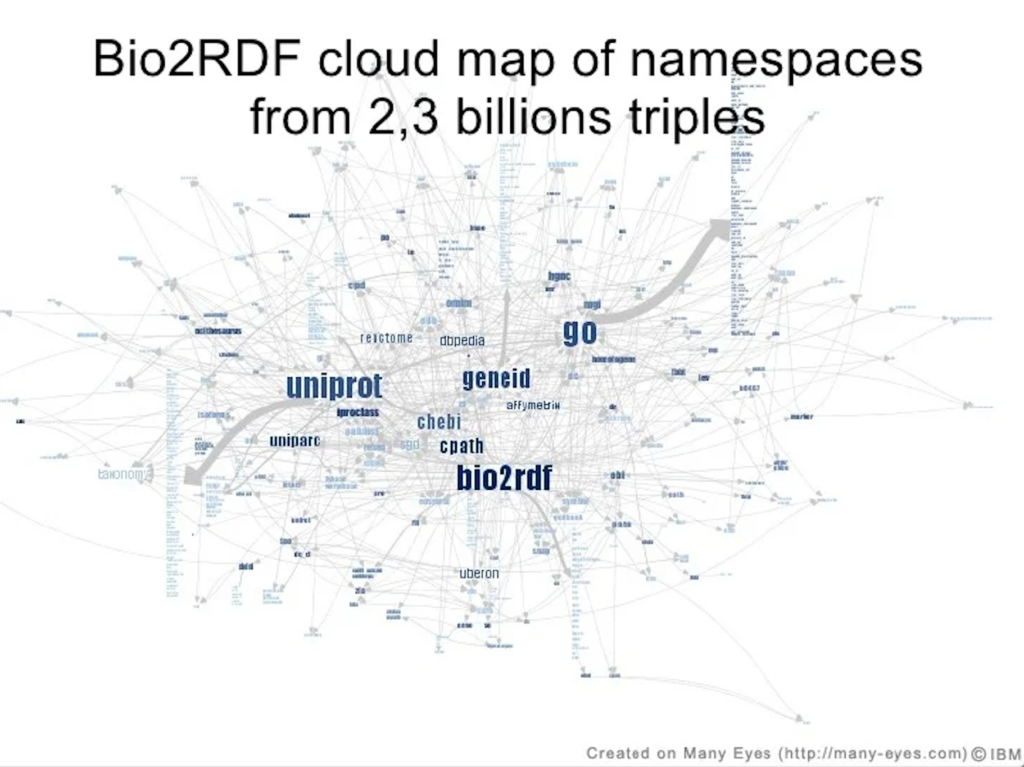
Bio2RDF is a project that provides RDF versions of several bioinformatics databases, such as UniProt, PDB, and DrugBank. You can use its SPARQL endpoint to retrieve information on proteins, drugs, and biological pathways.
A SPARQL endpoint is essential for creating powerful applications and services. It allows data providers to make their data more accessible to a wider range of users and applications. It offers extensive flexibility for data queries and supports a variety of content types for query solution documents (HTML, JSON, CSV, RDF-XML, etc.). This makes it an ideal choice for accessing, retrieving, and manipulating data stored in RDF in knowledge graphs.
At Cognizone, we understand the full potential of a SPARQL endpoint flexibility and interoperability, and the ability to connect and use Linked Data. We strive to share our knowledge and skills, and this is a great opportunity for us to share our expertise on this powerful tool and its role in the Linked Data and Semantic Web space.
We appreciate the time you took out of your day to read this article and we hope you found it informative!
You can find more articles on our blog and while you’re there take a look at our resources and insights about building an effective Enterprise Knowledge Graph.
For news and insights find us on Twitter @cognizone
Interested in building a SPARQL endpoint? Contact us at info@cogni.zone
We are a specialist consultancy with long experience in designing and implementing Enterprise Knowledge Graphs in government and other data-intensive sectors. Through our combination of technical skills, industry practitioners, and expertise in open and linked data, we can help you see data challenges from a new perspective.